⚡️ TL;DR
In this post, I will discuss how to build a system from scratch that supports a single user and gradually scales to support one million users.
Single server architecture
When you are starting a new project, you typically start with a single server architecture. This architecture is simple to set up and easy to maintain but everything is running on one server: web app, database, cache, etc.
To understand how the single server architecture works, let’s take a look at the following diagram and the request flow:
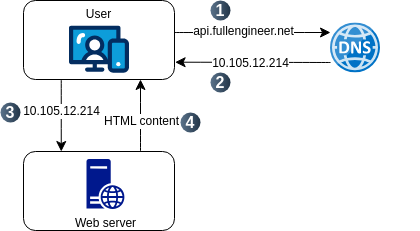
-
The user access the site through domain names, e.g.,
api.fullengineer.netorwww.fullengineer.net. Usually, the Domain Name System (DNS) is a paid service provided by a third party. -
IP address of the server is resolved by the DNS server and returned to the client.
-
Hypertext Transfer Protocol (HTTP) request is sent to the server.
-
The server processes the request and sends back the response to the client.
The traffic source depends on web application or mobile application. Web application uses a combination of server-side languages like PHP, Ruby, Python, etc., and client-side languages like HTML, CSS, and JavaScript. Mobile application uses a combination of server-side languages like Java, Swift, Kotlin, etc., and client-side languages like React Native, Flutter, etc.
In general the communication process is the same for both web and mobile applications and the data received is in Javascript Object Notation (JSON) format. Here is an example of a JSON response:
Adding a database
With the growth of the user base, the single server architecture will not be able to handle the load. To scale the system, we need multiple servers. The first step is to move the database to a separate server. This architecture is called a two-tier architecture allowing them to scale independently.
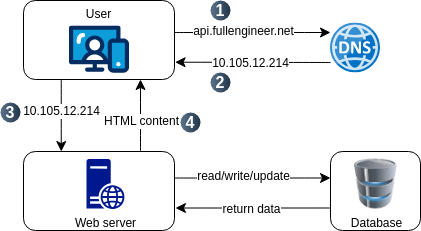
Now the thing is which database to choose. There are two types of databases: SQL and NoSQL. SQL databases are good for complex queries and transactions since the represent and store data in tables and rows, where we can perform join operations using SQL accross diferent tables.The most popular SQL databases are MySQL, PostgreSQL, and Oracle. NoSQL databases are good for large amounts of data and are horizontally scalable and they are grouped into four categories: key-value stores, document stores, column-family stores, and graph databases. Where joins are not possible and data is stored in a non-tabular format. The most popular NoSQL databases are MongoDB, Cassandra, and Redis.
Usually the choice of database depends on the type of data and the type of queries that need to be performed. For example, if the data is structured and the queries are complex, then SQL databases are a good choice. On the other hand, non-relationa databases might be a good choice if:
- The data is unstructured or semi-structured.
- The application requires super-low latency.
- The application needs to handle a huge amount of data and traffic.
- The application only needs to serialize and deserialize data such us JSON, XML, YAML, etc.
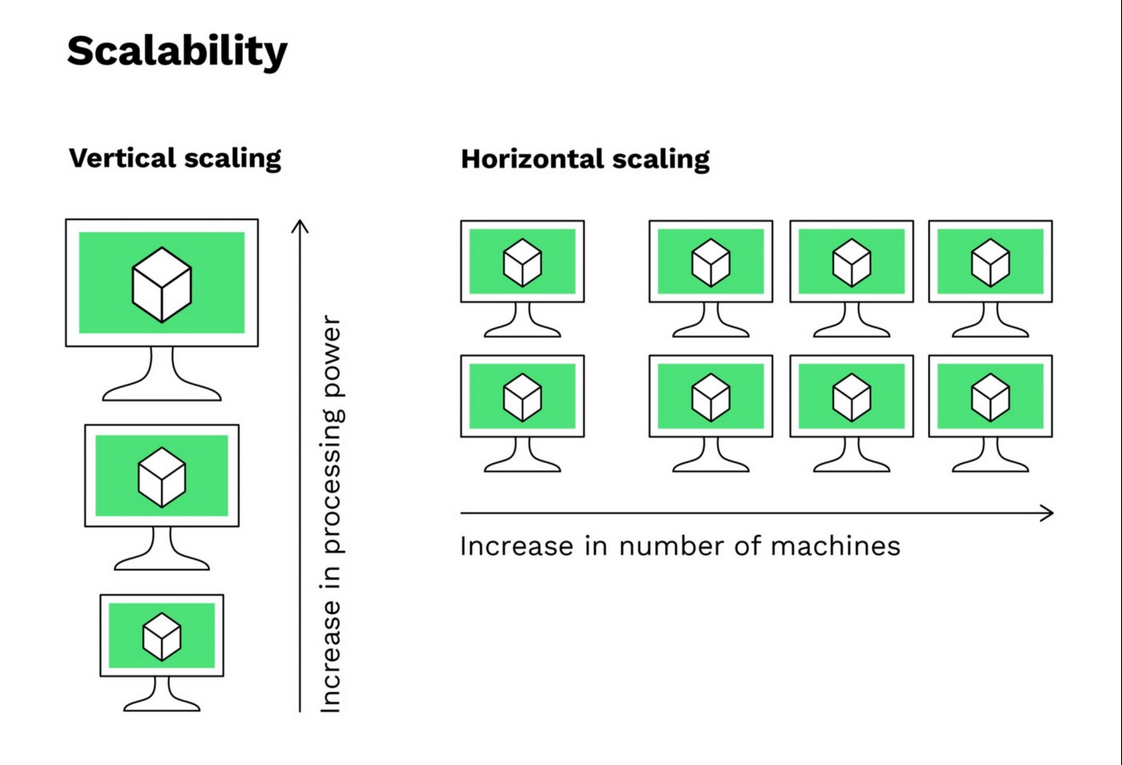
We will talk about scaling: vertical and horizontal scaling. Vertical scaling is adding more resources to a single server, such as CPU, memory, storage, etc. But has the limitation of the hardware and does not have redundancy for high availability. So if the server goes down, the whole system goes down. Horizontal scaling is adding more servers to the system, such as load balancers, web servers, database servers, etc. It has redundancy for high availability and can handle more traffic.
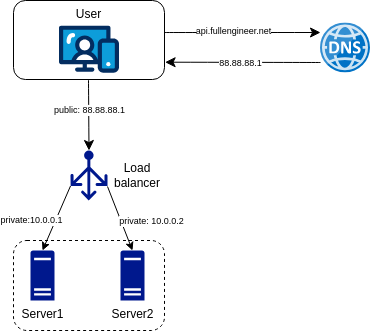
Adding a load-balancer
Once we definitely need to scale the system, we need to add a load balancer to distribute the incoming traffic across multiple servers. This architecture is called a three-tier architecture.
With this setup, web servers are not reachable anymore from the client side. The client communicates with the load balancer, which then forwards the request to one of the web servers. The web server processes the request and sends back the response to the client through the load balancer.
- If server 1 is down, the load balancer will forward the request to server 2. This is called high availability. We need to incluse a new healthy web server to pool to balance the load.
- If the traffic increases, we can add more web servers to the pool. This is called horizontal scaling.
Database replication
The best way to achieve high availability for the database is to replicate it. Database replication is the process of copying data from one database to another database. The primary database is called the master database, which is responsible for writing data. The secondary database is called the slave database, which is responsible for reading data.
Most applications require a much higher ratio or reads to writes. This, the number of slaves databases is usually larger than the number of master databases.
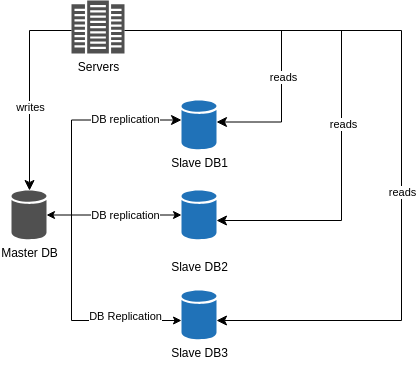
This model improves performance because more queries can be processed in parallel. It also improves fault tolerance because if the master database goes down, one of the slave databases can be promoted to the master database.
In production systems, promoting a new master is more complicated as the data in a slave database is not always up-to-date with the data in the master database. To solve this problem, we can use a distributed database like Cassandra, which is designed to handle large amounts of data across many commodity servers, providing high availability and fault tolerance.
Let’s see how the system is working now:
-
A user gets the IP address of the load balancer from DNS.
-
The user ocnnects to load balancer with this IP address.
-
The load balancer forwards the HTTP request to one of the web servers.
-
The web server reads user data from a slave database.
-
The web server routes data-modyfing requests to the master database.
Now it is time to improve the load/response time of the system.
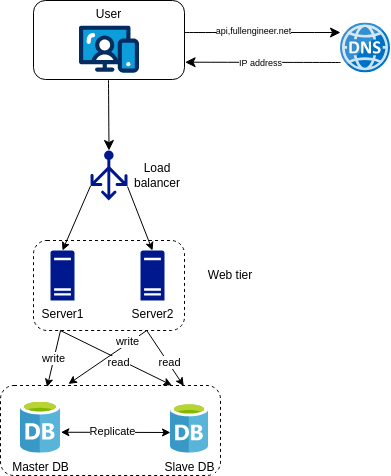
Adding a cache
A cache is a temporary storage that stores frequently accessed data. It is used to reduce the load on the database and improve the response time of the system.
After receiving a request, the web server checks the cache first. If the data is found in the cache, the web server returns the data to the client. If the data is not found in the cache, the web server reads the data from the database, stores it in the cache, and then returns the data to the client.
There are few consideration fo r using a cache:
-
When to use a cache: Use a cache when the data is read frequently and the data is not updated frequently.
-
Expiration policy: Set an expiration time for the data in the cache. This is to ensure that the data in the cache is not stale.
-
Consistency: Make sure that the data in the cache is consistent with the data in the database. When the data in the database is updated, the data in the cache should be invalidated.
-
Cache eviction policy: When the cache is full, the cache needs to evict some data to make room for new data. There are several cache eviction policies, such as Least Recently Used (LRU), Least Frequently Used (LFU), and First In First Out (FIFO).
-
Mitigation failures: When the cache is down, the web server should still be able to serve the request. One way to achieve this is to use a write-through cache, where the web server writes the data to the cache and the database at the same time.
Content Delivery Network (CDN)
a CDN is a network of servers distributed geographically that store cached content. It is used to reduce the load on the web server and improve the response time of the system.
When a user requests a file, the CDN checks if the file is in the cache. If the file is found in the cache, the CDN returns the file to the user. If the file is not found in the cache, the CDN requests the file from the web server, stores it in the cache with a HTTP heate Time-to-Live (TTL) describing how long the file is cached, and then returns the file to the user.
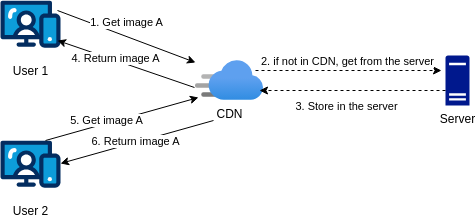
The main constraint of the CDN is the cost since they are run by third-party companies and they charge based on the amount of data transferred. Also is importanto to set an appropriate TTL to avoid serving stale data even prepare some strategy when the CDN is down.
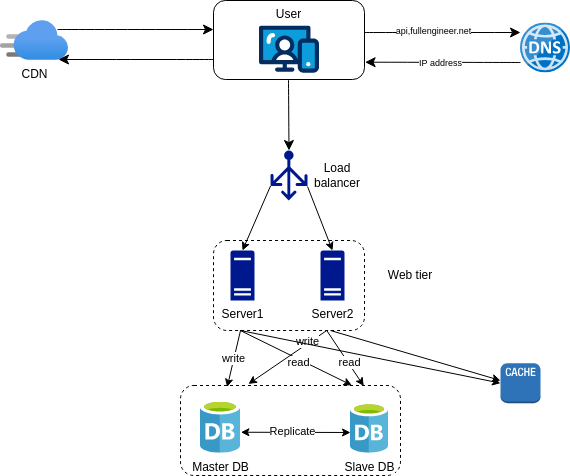
Below is the final architecture of the system where static assets (JS, CSS, images, etc.) are served by the CDN and dynamic content is served by the web server while the database liad is ligthened by caching the data.
Stateless web tier
Now it is time to improve the scalability of the system. For this, we need to move state (user session data) out of the web tier. A good practice is to store this session data in a persistent storage like a database or a cache where each server in the cluster can aceess it. This architecture is called a stateless web tier.
The opposite of a stateless web tier is a stateful web tier where the session data is stored in the memory of the web server. This architecture is not scalable because the session data is lost when the web server goes down.
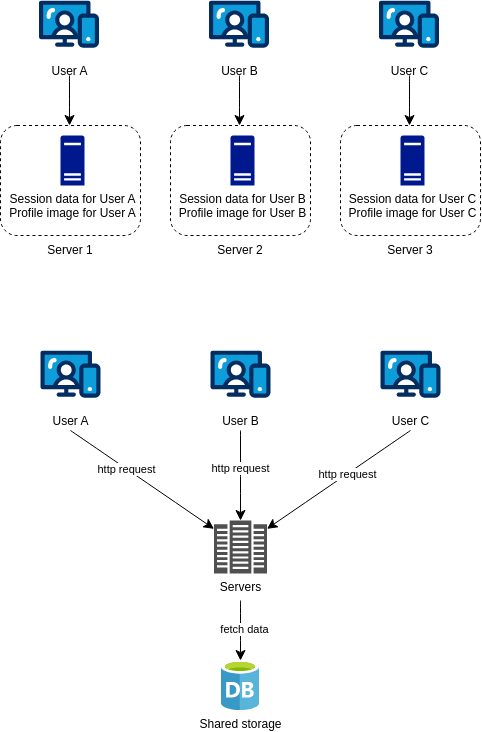
The issue with stateful web tier is that every request from the same cliente must be routed to the same server. This is called session affinity or sticky session. This is not scalable because the load balancer needs to keep track of the session data and route the request to the same server, this adds an overhead to the load balancer.
However, the stateless web tier is scalable because the HTTP request can be routed to any server in the cluster, which fetch state data from a shared data store.
Next graph shows the updated architecture with the stateless web tier:
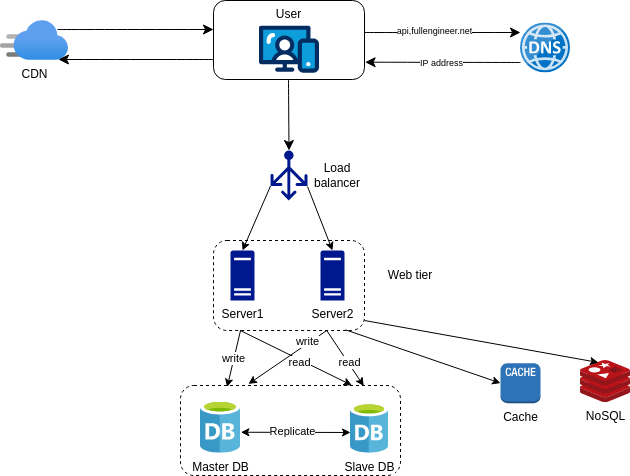
The shared data store could be a relational database, a NoSQL database, or a cache. The choice of NoSQL is as it is easy to scale. Autoscaling means adding or removing web servers automatically based on th traffic load.
Data centers
When the app grows and attracts a significant of number of useres internationally, it is time to improve the availability of the system across wider geographical areas. This can be achieved by deploying the system in multiple data centers.
in the event of a data center failure, the traffic can be routed to another data center. This is called disaster recovery.
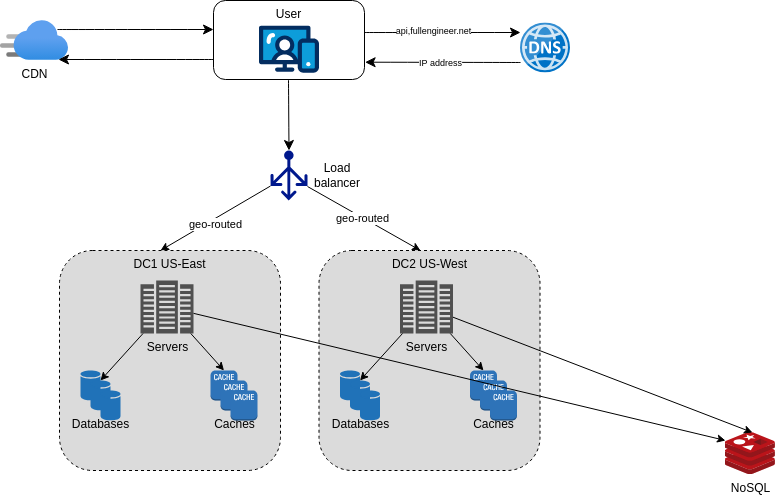
One of the technical challenges of deploying the system in multiple data centers is data synchronization. Users from different regions could use differentlocal databases or caches. In failover cases, the data in the local database or cache could be stale. A common strategy is to replicate the data across data centers using a distributed database like Cassandra.
With multi-data center setup, it is important to test the application at different locations. Automated deployment tools are vital to keep the system up and consisten throughout the data centers.
Message queues
To further scale our system, we need to decouple different components so the can be scaled independently. One way to achieve this is by using message queues. A message queue is a strategy employed by many real-time applications to handle the large volume of messages that are passed between different components of the system.
A message queue is a system that allows different components of a system to communicate with each other by sending messages. The message queue acts as a buffer between the sender and the receiver. The sender sends a message to the message queue, and the receiver reads the message from the message queue.
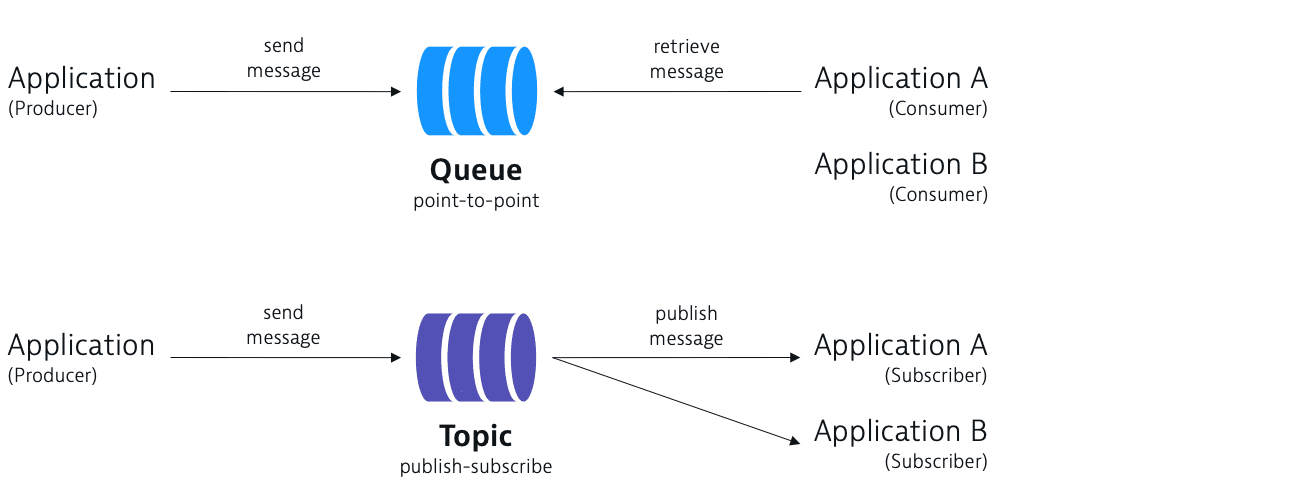
With the message queue, the produce can post a message to the queue and the consumer can read the message from the queue. The message queue can be used to decouple different components of the system, so they can be scaled independently.
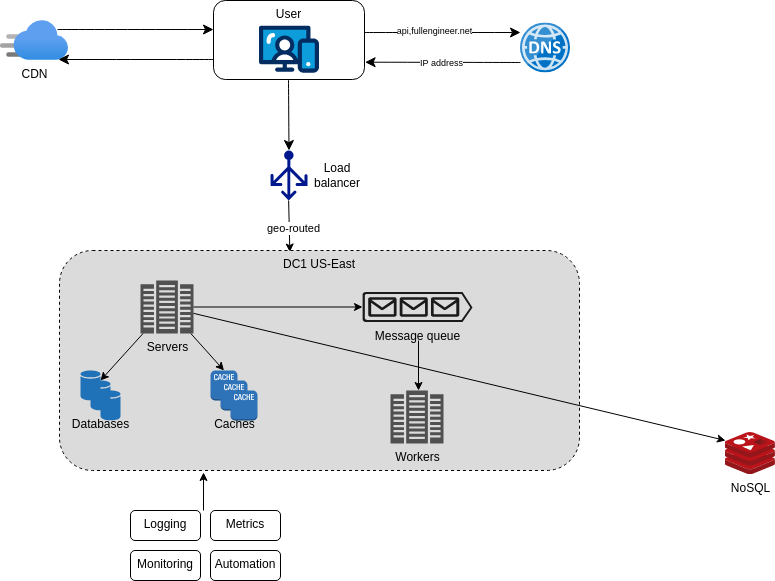
Imagine that the application supports photo customization. Those customization tasks take time to complete. Photo processing workers pick up jobs from the message queue and asynchronously perform photo customization. This way, the web server can respond to the user quickly without waiting for the photo customization to complete.
When the size of the message queue grows, we can add more photo processing workers to the system and if the queue is empty, we can remove some workers. This is called autoscaling.
Logging and metrics
When working with a small application, it is easy to debug and monitor the system. But as the application grows, it becomes more difficult to debug and monitor the system. To solve this problem, we need to log and monitor the system.
Logging is the process of recording events that happen in the system. Logs are useful for debugging and troubleshooting the system. We can monitor error logs at per server level or use tools like Logstash, Splunk, or Sumo Logic to aggregate logs from multiple servers.
Metrics are used to measure the performance of the system. Metrics are useful for monitoring the system and identifying bottlenecks. We can use tools like Graphite, Grafana, or Datadog to collect and visualize metrics.
These tools leverage automation to monitor the system and alert the team when something goes wrong. This is called monitoring as a service.
Including the logging and metrics in the system we are able to monitor the system and identify bottlenecks. This is the final architecture of the system:
Database scaling
As the data grows exponentially, the database gets more overloaded. To solve this problem, we need to scale the database. There are two ways to scale the database: vertical scaling and horizontal scaling.
Vertical scaling is adding more resources to a single server, such as CPU, memory, storage, etc. This is called scaling up. The limitation of vertical scaling is the hardware limitation. The server can only handle a certain amount of resources but the overall cost is high since powerful servers are expensive.
Horizontal scaling is adding more servers to the system, such as load balancers, web servers, database servers, etc. This is called scaling out. The advantage of horizontal scaling is that it is cost-effective and can handle more traffic.
Sharding separates the data into multiple databases. Each database is called a shard. The data is distributed across multiple shards based on a shard key. In this way, the data can be served based on the shard key that can be a user ID, a timestamp, or even a hash function.
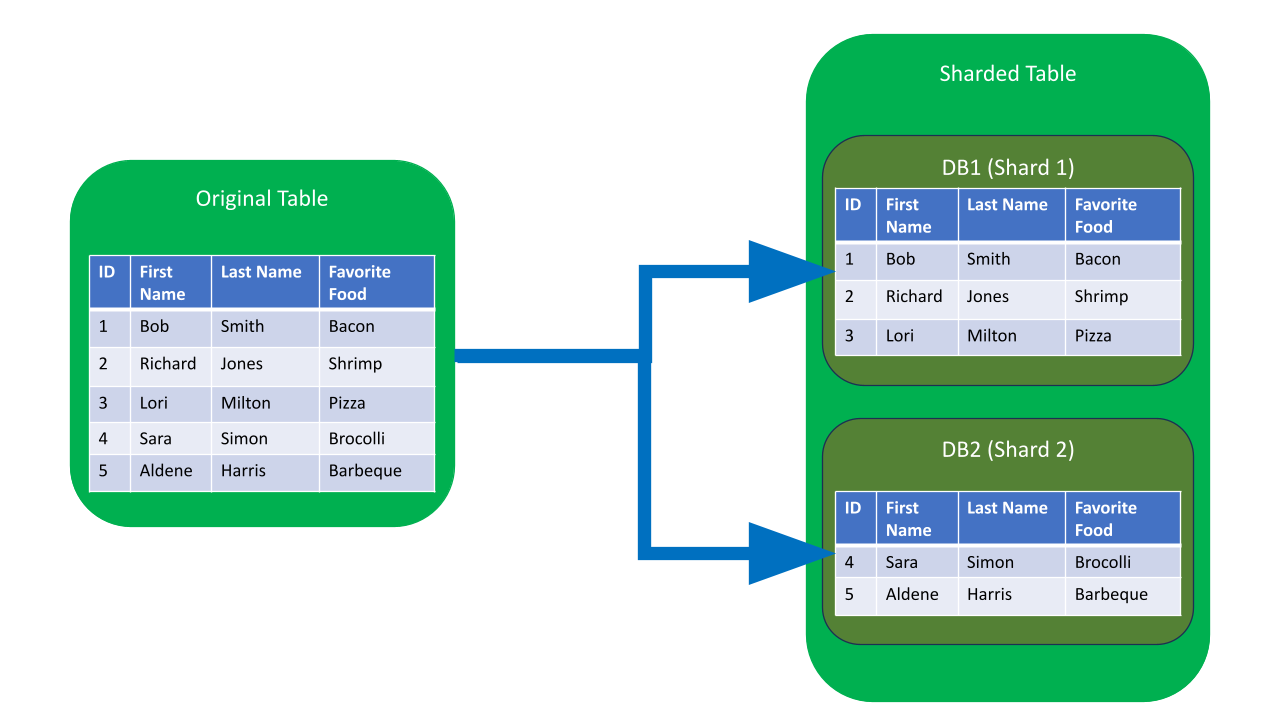
The most important thing to consider when sharding is the shard key. The shard key should be evenly distributed across all shards. If the shard key is not evenly distributed, some shards will be overloaded while others are underloaded.
Sharding is a great technique to scale the database but it is complex to implement. It requires a lot of effort to shard the database and maintain the shards. For example, resharding data is needed when the data grows rapidly or when the shard key is not evenly distributed. Also it exists the celebrity problem where a shard becomes a hotspot because of the high traffic on a single shard. The last issue is the join problem where joins are not possible across different shards. A common solution is to denormalize the data so that queries can be performed on a single table.
And that’s it! We have built a system from scratch that supports a single user and gradually scales to support one million users. I hope you enjoyed this post and learned something new. If you have any questions or feedback, feel free to send me an email. Thanks for reading!